
[알린이의 코테 입문 #009 - 012] 사칙연산, 배열, 수학
Category: Programmers
태그: Programmers
📍 사칙 연산, 배열, 수학
🔎 문제 1. 나머지 구하기
🤔 나의 풀이
using System;
public class Solution
{
public int solution(int num1, int num2)
{
return num1 % num2;
}
}
🔎 문제 2. 중앙값 구하기
먼저 조건에 값을 정렬하는 것이 있다. 버블 정렬을 이용한다.
버블 정렬 알고리즘은 따로 빼서 정리하겠음.
// 버블 소팅
public static int[] solution(int[] array)
{
//var result = 0;
for (var i = 0; i < array.Length - 1; i++)
{
for (int j = 0; j < array.Length - 1; j++)
{
if (array[j] > array[j + 1])
{
var temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
}
}
}
return array;
}
위와 같은 방법으로 정렬을 할 수 있는데, 여기서 if 본문을 한번 더 줄일 수 있다.
// 줄이기 전
if (array[j] > array[j + 1])
{
var temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
}
// 줄인 후
if (array[j] > array[j + 1])
{
(array[j], array[j + 1]) = (array[j + 1], array[j]);
}
둘은 같다.
이제 중앙 값을 도출하는 부분만 남았는데, 첫 번째 조건에 array의 길이는 홀수가 있었다는 사실을 잊으면 안됨 따라서 짝수는 고려할 필요 없음.
3, 5, 7, 9, 11 … 에 해당하는 중앙 값을 찾으면 된다.
var middleIndex = array.Length / 2; // 가운데 인덱스 계산
var middleValue = array[middleIndex] // 가운데 값 찾기
🤔 나의 풀이
using System;
public class Solution
{
public int solution(int[] array)
{
for(int i = 0; i < array.Length - 1; i++)
{
for(int j = 0; j < array.Length - 1; j++)
{
if(array[j] > array[j + 1])
{
var temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
// C# 7.0 부터 위의 본문을 아래와 같이 튜플로 쉽게 Swap할 수 있는데 프로그래머스 에디터가 인식을 못함.
//(array[j], array[j + 1]) = (array[j + 1], array[j]);
}
}
}
var middleIndex = array.Length / 2;
return array[middleIndex];
}
}
버블 정렬을 이용해서 구현하면 확실히 코드의 줄이 길어진다.
그렇다면 C#의 꽃이라고 불리는 LINQ를 사용해보자.
아래는 LINQ를 써서 간단하게 끝난 코드이다.
using System;
using System.Linq;
public class Solution
{
public int solution(int[] array)
{
int answer = array.OrderBy(x => x).ToArray()[array.Length / 2];
return answer;
}
}
물론 LINQ를 사용하면 네임스페이스를 제외한 줄 수가 단 한 줄이 나온다.
하지만, 이 연산만을 위해서 LINQ를 사용하는 것은 주관적인 생각으로 별로라고 생각한다.
왜냐하면 LINQ는 무겁다.
편리한 만큼 정말 많은 기능들을 가지고 있기 때문에, 사용하는 데 있어서 많이 고려해보고 사용해야 한다고 생각한다.
성능 향상은 단지 코드의 줄 수를 한 줄이라도 줄여서 보여 주기 위함이 아닌, 실질적으로 코드 내부에서 진행되는 불필요한 기능들을 없애는 게 더 중요하다고 생각한다.
🔎 문제 3. 최빈값 구하기

풀이의 순서를 먼저 정해보자. 먼저 매개변수로 받은 배열 A의 중복을 제거하고 나서의 배열 사이즈를 알아야 한다. 그리고 그 배열사이즈로 temp 배열들 B, C를 만든다. B에는 중복을 제거한 배열을 넣는다.
이중 for문을 써서 첫 번째 for문은 A 배열을 순회하고 안의 for문은 B 배열을 순회하면서 요소를 비교한다 if문을 이용하여 A 배열 요소의 값과 B 의 배열 요소의 값이 각각 같으면, 해당 B 배열의 인덱스와 매칭되는 C 배열을 ++ 해준다.
그리고 마지막으로 C 배열 요소중 가장 큰 값을 Enumerable.Max() 메서드를 이용해서 가져와 리턴한다. 나는 위와 같이 생각했는데, 다른 풀이 방법도 존재헀다.
다른 풀이 방법은 이러하다. 먼저 매개변수로 받은 배열 A의 중복을 제거한 배열 B를 만든다. 배열 B의 길이와 같은 배열 C를 만든다.
이중 for문을 사용해서 첫 번째 for문은 중복을 제거한 배열 B를 순회하고, 중복 카운트를 할 정수형 지역변수를 for문 내부에 하나 선언한다.
두 번째 for 문은 배열 A를 순회하면서 배열 B의 i번째 요소와 배열 A의 j번째 요소가 같다면 count++ 를 해주고, 두 번째 for문이 종료되면 배열 C의 i번째 요소에 count 값을 할당해준다.
그리고 문제에서 최빈값이 2개 이상일 경우 -1를 반환하고 1개일 경우, 그 최빈 값을 그대로 반환해야 한다고 했기 때문에, if문으로 배열 C의 길이와 배열 C의 중복을 제거한 요소의 길이를 비교해서 다를 경우 -1을 반환하게 만들어 주는 예외만 작성해주면 될 것이다.
위의 내용을 코드로 작성해보자
🤔 나의 풀이
using System;
using System.Linq;
public class Solution
{
public int solution(int[] array)
{
var distinct = array.Distinct().ToArray(); // 중복을 제거한 배열
var arrTemp = new int[distinct.Length]; // 중복을 제거한 배열의 길이만큼의 배열 생성
for (var i = 0; i < distinct.Length; i++)
{
var count = 0;
for (var j = 0; j < array.Length; j++)
{
if (distinct[i] == array[j])
count++;
}
arrTemp[i] = count;
}
if (arrTemp.Length != arrTemp.Distinct().Count())
return -1;
return arrTemp.Max();
}
}
위와 같은 코드를 작성해서 제출했는데, 정답이 틀렸다.
다시 한번 확인해 보니
if (arrTemp.Length != arrTemp.Distinct().Count())
return -1;
이 부분의 if문 조건이 무조건 true가 나와서 -1만 반환된다.
왜냐하면 중복을 제거한 숫자 요소들이 배열에 있는게 아니라 count된 숫자가 요소로 들어있기 때문이다.
예를 들어 {1, 2, 3, 3, 3, 4} 과 같은 배열을 매개변수로 넘겼을 경우,
아래에서 받게 되는 distinct(배열 B)의 요소들은 {1, 2, 3, 4} 이고, 최종적으로 arrTemp(배열 C)의 요소들은 {1, 1, 3, 1} 이된다.
따라서 여기서 중복을 없앤 배열의 길이는 2가 되기 때문에 false 값이 나오는 것이다.
그렇다면 어떻게 해결해야 할까?
어쩌면 이상한 곳에서 헤매고 있는 걸지도 모르겠다.
무식하게 for문을 하나 더 추가했다.
using System;
using System.Linq;
public class Solution
{
public int solution(int[] array)
{
var distinct = array.Distinct().ToArray(); // 중복을 제거한 배열
var arrTemp = new int[distinct.Length]; // 중복을 제거한 배열의 길이만큼의 배열 생성
for (var i = 0; i < distinct.Length; i++)
{
var count = 0;
for (var j = 0; j < array.Length; j++)
{
if (distinct[i] == array[j])
count++;
}
arrTemp[i] = count;
}
// if (arrTemp.Length != arrTemp.Distinct().Count())
// return -1;
//
// return arrTemp.Max();
var cnt = 0;
for (int i = 0; i < arrTemp.Length; i++)
{
if (arrTemp.Max() == arrTemp[i])
cnt++;
}
return cnt > 1 ? -1 : arrTemp.Max();
}
}
위와 같이 제출을 했는데,
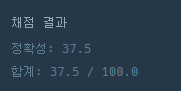
아주 멋진 정확성이 나왔다.
조금 더 수정이 필요하다.
근데 전혀 모르겠다.
왜 정확성이 37.5%가 나오는 걸까?
내가 알지 못하는 구간에서 예외가 발생하고 있다는 건데..
이건 뭐 감도 안오네;;
애초에 내가 왜 틀렸는지도 모르겠다.
그래서 생각을 완전히 전환해서 딕셔너리로 접근해봤다.
using System;
using System.Linq;
public class Solution
{
public int solution(int[] array)
{
// 딕셔너리를 사용해보자
var frequency = new Dictionary<int, int>();
var answer = 0;
foreach (var num in array)
{
if (frequency.ContainsKey(num))
frequency[num]++;
else
frequency[num] = 1;
}
var arrFre = frequency.Values.ToArray();
var maxFrequency = arrFre.Max();
var count = 0;
for (var i = 0; i < frequency.Values.Count; i++)
{
if (arrFre[i] == maxFrequency)
count++;
}
answer = maxFrequency;
if (count > 1)
{
answer = -1;
}
return answer;
}
}
위와 같은 코드로 작성해서 다시 제출.
처음과 동일하게 37.5점이 나왔다.
따라서 무언가 공통적인 문제가 있다는 것을 도출할 수 있다.
최빈값을 구하는 알고리즘을 찾아보았다.
static void Main()
{
//① 입력: 범위는 0부터 n점까지 점수만 들어온다고 가정
int[] scores = { 1, 3, 4, 3, 5 }; //0~5만 들어온다고 가정
int[] indexes = new int[scores.Max() + 1]; //0~5의 점수 인덱스 개수 저장
int max = int.MinValue; //MAX 알고리즘 적용
int mode = 0; //최빈값이 담길 그릇
//② 처리: Data -> Index -> Count -> Max -> Mode
for (int i = 0; i < scores.Length; i++)
{
indexes[scores[i]]++; //COUNT
}
for (int i = 0; i < indexes.Length; i++)
{
if (indexes[i] > max)
{
max = indexes[i]; //MAX
mode = i; //MODE
}
}
//③ 출력
Console.WriteLine($"최빈값(문) : {mode} -> {max}번 나타남");
var q = scores.GroupBy(v => v).OrderByDescending(g => g.Count()).First();
int modeCount = q.Count();
int frequency = q.Key;
Console.WriteLine($"최빈값(식) : {frequency} -> {modeCount}번 나타남");
}
나는 여기서 절대로 이해할 수 없었던 부분이 있는데, 배열 내의 요소에서만 카운팅을 하는 것이 아닌 0에서 부터 배열 내의 요소 중 가장 큰 값까지의 범위를 전부 순회하면서 카운팅을 하는 부분이 정말 이해하기 어려웠다.
대체 왜? 배열의 요소에 없는 수 까지 카운팅을 하는 걸까?
//① 입력: 범위는 0부터 n점까지 점수만 들어온다고 가정
int[] scores = { 1, 3, 4, 3, 5 }; //0~5만 들어온다고 가정
int[] indexes = new int[scores.Max() + 1]; //0~5의 점수 인덱스 개수 저장
int max = int.MinValue; //MAX 알고리즘 적용
int mode = 0; //최빈값이 담길 그릇
MAX 알고리즘이라고 주석이 걸려 있는 부분이 있는데 MAX 알고리즘은 무엇일까?
일단 넘어 가고,
위의 코드를 보면 범위를 배열 내의 요소중 가장 큰 수에 +1를 하고 그 길이로 배열을 만드는 것을 볼 수 있다.
//② 처리: Data -> Index -> Count -> Max -> Mode
for (int i = 0; i < scores.Length; i++)
{
indexes[scores[i]]++; //COUNT
}
위의 코드를 처리하면 scores.Length 즉 5번 for문을 반복한다.
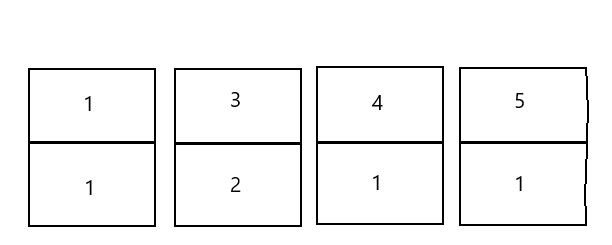
본문에는 indexes[scores[i]]++; 라는 코드가 작성되어 있고,
indexes[1]++;
indexes[3]++;
indexes[4]++;
indexes[3]++;
indexes[5]++;

for문의 반복이 끝난 뒤는 위와 같을 것이다.
그림으로 그려보니 왜 요소에서 가장 큰 값 + 1의 길이로 배열을 생성하는 지 이해할 수 있었다.
그 후의 반복문은
for (int i = 0; i < indexes.Length; i++)
{
if (indexes[i] > max)
{
max = indexes[i]; //MAX
mode = i; //MODE
}
}
indexes.Length 즉 6번 반복한다.
현재 인덱스의 배열 내 요소가 max보다 크다면 max에 요소의 값을 넣고, mode(최빈값 변수)에 현재 인덱스 i를 넣는다.
왜냐하면 인덱스와 매칭되는 것이 score 배열의 요소 값이기 때문이다.
//③ 출력
Console.WriteLine($"최빈값(문) : {mode} -> {max}번 나타남");
첫번째 출력문은 "최빈값(문) : 3 -> 2번 나타남" 일 것이다.
var q = scores.GroupBy(v => v).OrderByDescending(g => g.Count()).First();
int modeCount = q.Count();
int frequency = q.Key;
Console.WriteLine($"최빈값(식) : {frequency} -> {modeCount}번 나타남");
해당 부분은 위의 MAX, 개수 알고리즘을 LINQ을 사용해 단 3줄로 줄인 것이다.
코드를 순서대로 읽어보면 scores 배열에서 각각의 요소들로 GroupBy를 사용해 그룹을 만들어준다.
scores는 int 배열이기 때문에 IGrouping<int, int>[] Key, Value 형식으로 그룹화가 된다.
그리고 만들어진 배열을 Count()을 기준으로 내림차순 정렬 후 First() 반환 메서드로 최상단에 있는 배열을 반환 받는다.
modeCount에 개수의 값을 넣고, frequency에 최빈값을 넣는다.
따라서 "최빈값(식) : 3 -> 2번 나타남" 와 같이 출력된다.
최빈값을 구하는 방법을 알았으니, 이제 최빈값이 2개 이상 인지 아닌지 체크하는 부분 그리고 처리하는 부분 코드만 작성하면 된다.
using System;
using System.Linq;
public class Solution
{
public int solution(int[] array)
{
var query = array.GroupBy(v => v).OrderByDescending(g => g.Count()).First();
var modeCount = query.Count();
var frequency = query.Key;
var arrTemp = array.GroupBy(v => v).Where(x => x.Count() == modeCount).ToArray();
if(arrTemp.Length > 1)
return -1;
else
return frequency;
}
}
LINQ를 사용해서 윗부분은 그대로 가져오고, 아래부분(최빈값이 2개 이상인 경우, 그에 따라 처리하는 부분)
var arrTemp = array.GroupBy(v => v).Where(x => x.Count() == modeCount).ToArray();
if(arrTemp.Length > 1)
return -1;
else
return frequency;
일단 나는 array의 배열 각 요소를 그룹핑해서 IGrouping<int, int> 형으로 만들고 그 안에서 최빈값의 카운트 수와 비교해서 같은 요소를 가져와 배열로 변환한다.
카운트가 1보다 클 경우 -1 반환.
카운트가 1이거나 작을 경우, 그 최빈값 그대로 반환.

드디어 !!
무려 11점이나 하네..
🤔 다른 사람의 풀이 확인
눈에 띄게 괜찮은 코드 풀이만 분석할 생각이다.
⚒️ 1번 풀이
using System;
using System.Linq;
public class Solution
{
public int solution(int[] array)
{
var list = array.GroupBy(x => x, g => g, (x, g) => new { n = x, cnt = g.Count() });
var max = list.Where(x => x.cnt == list.Max(o => o.cnt));
int answer = max.Count() == 1 ? max.First().n : -1;
return answer;
}
}
코드를 읽어보면, list라는 변수를 만드는 것을 볼 수 있는데, IEnumerable<int n, int cnt> 형식이다.
array 배열에서 GroupBy 메서드에 매개변수를 마구마구 넣어 호출하는 것을 볼 수 있는데, 이건 좀 있다 정리하고
바로 아래 max라는 변수가 보인다.
이 친구도 IEnumerable<int n, int cnt> 형식으로 Key, Value로 이루어져 있다.
list 변수에 Where 메서드를 통해 value를 cnt와 현재 list 변수에서 가장 높은 cnt를 가진 값과 비교해서 같은 애들만 가지고 온다. 그리고 max의 Count() 반환 값이 1과 같으면 max.First() 즉 첫번째의 키값에 해당하는 n을 반환하고, 아니면 (최빈값이 2개 이상) -1을 반환한다.
⚒️ GroupBy 메서드에 매개변수 마구 넣은 부분 정리
여기가 확실하게 이해가 가지 않아서 정리를 해두려고 한다.

보면 파라미터가 총 4개다.
this가 찍힌 첫 번째를 제외하고 두 번째부터 보면 되는데 차례대로 keySelector, elementSelector, resultSelector 라는 이름을 가졌다.
위의 코드를 배경삼아 본다면, “x => x” 가 keySelector에 해당하는 부분이고 “g => g”가 elementSelector에 해당하는 부분이며, “(x, g) => new { n = x, cnt = g.Count()}” 가 resultSelector에 해당하는 부분이다.
0번째 매개변수 <TSource> == 요소를 그룹화할 IEnumerable<T>
1번째 매개변수 <TSource, TKey> == 각 요소에 대한 키를 추출하는 기능
2번째 매개변수 <TSource, TElement> == 각 소스 요소를 IGrouping<TKey, TElement> 의 요소에 매핑하는 함수
3번째 매개변수 Func <TKey, IEnumerable<TElement> , TResult> == 각 그룹에서 결과 값을 생성하는 기능
내가 생각하기에는 근데 사실 매개변수가 3개인 함수를 호출하지 않아도 될 것 같다는 생각이 들었다.
어차피 Key로 그룹화 하면 자동으로 value 값의 개수가 Count와 같다.
using System;
using System.Linq;
public class Solution
{
public int solution(int[] array)
{
var list = array.GroupBy(x => x).ToArray();
var max = array.GroupBy(x => x).Where(x => x.Count() == list.Max(o => o.Count())).ToArray();
return max.Length == 1 ? max.First().Key : -1;
}
}
위의 코드는 다른 사람의 풀이를 보완한 코드이다.
먼저 불필요한 분류를 없앴고, 제일 중요한 변경점은 기존 코드에 “IEnumerable의 가능한 다중 열거” 문제가 있었다.
“IEnumerable의 가능한 다중 열거” 문제란 예를 들어 쿼리를 사용할 경우, 컬렉션을 두 번 열거해서 추가 작업을 수행하는 과정에서 런타임 내에 두 호출 사이 데이터베이스의 변경이 있을 경우 두 루프에서 서로 다른 값을 얻게 될 수도 있다.
👉 JetBrain Doc 자세한 내용은 여기서
ToArray() 메서드로 강제로 열거해서 위의 문제를 보완했다.
사실 이 코드말고는 어차피 LINQ를 불러왔는데 정말 비효율적인 방법으로 작성한 코드밖에 없었다.
🔎 문제 4. 짝수는 싫어요
🤔 나의 풀이
using System;
using System.Linq;
public class Solution
{
public int[] solution(int n)
{
var answer = new int[n + 1];
for (var i = 0; i <= n; i++)
answer[i] = i;
return answer.Where(x => x % 2 != 0).ToArray();
}
}
1의 주저도 없이 그냥 LINQ를 써버렸는데, LINQ로 더 깔끔하게 코드를 쓰는 다른 풀이가 있었다.
🤔 다른 사람의 풀이 확인
⚒️ 1번 풀이 - LINQ
using System;
using System.Linq;
public class Solution
{
public int[] solution(int n)
{
int[] answer = Enumerable.Range(1, n).Where(x => x % 2 == 1).ToArray();
return answer;
}
}
IEnumerable Range (int start, int count) 메서드는 start부터 count만큼 숫자 범위 집합을 생성해준다.
Where절 부터는 나와 코드가 같다.
⚒️ 2번 풀이 - 시프트 연산
2번 풀이는 LINQ를 사용하지 않고 시프트 연산을 이용한 풀이다.
using System;
public class Solution
{
public int[] solution(int n)
{
int[] answer = new int[(n + 1) / 2];
for (int i = 0; i < (n + 1) / 2; i++)
answer[i] = (i << 1) + 1;
return answer;
}
}
n이 10이라고 가정해보자.
그 아래에서 (n + 1) / 2 는 11 / 2 즉 5.5가 될 것이고, int 정수형이기 때문에 소수점은 날라간다.
그리고 for 문을 반복하는데 마찬가지로 11 / 2 = 5.5 => 5 만큼 반복하게 된다.
따라서 i 는 0 ~ 4의 값을 가질 것이고, answer[0 ~ 4]를 순회 하면서 ((0 ~ 4) « 1) + 1 연산을 한다.
// 0 => 0000000 => (0000000 << 1) = 0000000 = 0 + 1 = 1
// 1 => 0000001 => (0000001 << 1) = 0000010 = 2 + 1 = 3
// 2 => 0000010 => (0000010 << 1) = 0000100 = 4 + 1 = 5
// 3 => 0000011 => (0000011 << 1) = 0000110 = 6 + 1 = 7
// 4 => 0000100 => (0000100 << 1) = 0001000 = 8 + 1 = 9
시프트 연산을 한 뒤의 값은 이렇게 되고, 우리가 얻어야 할 값과 정확히 일치한다.
15를 대입해도 정확한 답이 나온다.
using System;
public class Solution
{
public int[] solution(int n) // n 에 15 대입
{
int[] answer = new int[8]; // (15 + 1) / 2
for (int i = 0; i < 8; i++) // (15 + 1) / 2
answer[i] = (i << 1) + 1; // i = 0 ~ 7
return answer;
}
}
// 0 => 0000000 => (0000000 << 1) = 0000000 = 0 + 1 = 1
// 1 => 0000001 => (0000001 << 1) = 0000010 = 2 + 1 = 3
// 2 => 0000010 => (0000010 << 1) = 0000100 = 4 + 1 = 5
// 3 => 0000011 => (0000011 << 1) = 0000110 = 6 + 1 = 7
// 4 => 0000100 => (0000100 << 1) = 0001000 = 8 + 1 = 9
// 5 => 0000101 => (0000101 << 1) = 0001010 = 10 + 1 = 11
// 6 => 0000110 => (0000110 << 1) = 0001100 = 12 + 1 = 13
// 7 => 0000111 => (0000111 << 1) = 0001110 = 14 + 1 = 15
시프트 연산을 이렇게 사용할 수도 있는데,
사실상 특정 조건에서만 사용할 수 있고, 성능에 중점을 두어야 하는 상황에서만 사용된다.
왜냐하면 가독성이 정말 별로이기 때문.
코드가 읽히는 게 아니라 연산을 해봐야 앎.
🤣 한마디
시프트 연산을 쓰는 이유는 성능에 초점을 두어야할 때 압도적으로 빠르기 때문.
하지만 가독성을 포기한다.
이 게시물에는 지극히 주관적인 생각이 포함되어 있습니다.
오류나 틀린 부분, 또는 수정해야 할 부분이 있다면 언제든지 댓글 혹은 메일로 지적 부탁드립니다.
Comment