
[C# 으로 이해하는 자료구조] 3. 연결리스트 극장 4부작 (1/4)
Category: Data Structure 1
태그: Data Structure 1
알라딘에 있는 Alex Lee님의 C#으로 이해하는 자료구조 책을 보고 공부하며 정리 및 요약한 게시글입니다.
종이서적을 별로 좋아하지 않기 때문에 링크는 전자책입니다.
🔔책 구매하기 링크
본 글은 내돈내산이기 때문에 다소 비판적인 내용이 있을 수도 있습니다.
💾 연결 리스트 (LinkedList)
🔖 연결 리스트의 기초 개념
각 노드가 데이터와 포인터를 가지고 있으면서 노드들이 한 줄로 쭉 연결되어 있는 방식으로 데이터를 저장하는 구조.
각 노드가 한방향으로 다음 노드를 가리키고 있는 리스트를 단일 연결 리스트(Singly Linked List)라고 하고, 각 노드가 양방향으로 이전 노드와 다음 노드를 모두 가리키는 경우 이중 연결 리스트(Doubly Linked List)라고 한다.
🔖 단일 연결 리스트 (Singly Linked List)
🔎한방향으로 노드들을 연결한 간단한 자료 구조.
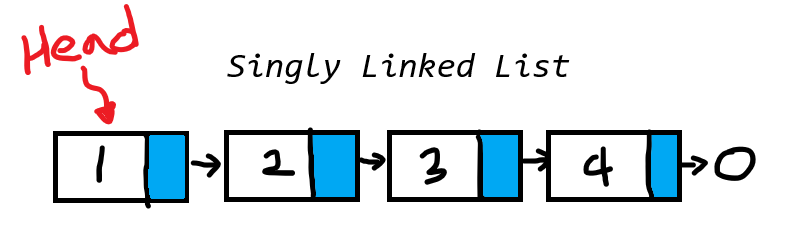
위의 이미지는 4개의 노드를 갖는 Singly Linked List의 예시이다.
Singly Linked List를 구현하기 위해서는 Node Class와 이들을 연결한 List인 Linked List Class를 만들면 된다.
Singly Linked List의 Node Class는 Node Data 필드와 다음 Node를 가리키는 Pointer를 가지고 있다.
📍 C# 으로 표현한 SinglyLinkedListNode Class
public class SinglyLinkedListNode<T>
{
public T Data { get; set; }
public SinglyLinkedListNode<T> NextNode { get; set; }
public SinglyLinkedListNode(T data)
{
Data = data;
NextNode = null;
}
}
Singly Linked List는 List의 첫 노드를 가리키는 Head 필드를 가지게 되고, 따라서 전체 List를 순차적으로 액세스 하려면 이 Head를 사용하면 된다.
Singly Linked List는 List의 기본적인 기능을 지원하기 위해서 아래와 같은 메서드를 구현한다.
1. Add(newNode) 메서드 - 새 Node를 추가.
2. AddAfter(curNode, newNode) 메서드 - 새 Node를 중간에 삽입.
3. GetNode(index) 메서드 - 지정한 위치에 있는 노드를 반환.
4. Remove(removeNode) 메서드 - 특정 노드를 지움.
5. 등등
📍 Add(newNode) 메서드
List가 비어 있을 경우 newNode를 할당하고, 비어있지 않으면 마지막 Node를 찾아 이동한 후 마지막 Node 다음에 newNode를 추가한다.
public void Add(SinglyLinkedListNode<T> newNode)
{
if (head != null) // 리스트가 비어 있지 않으면
{
var current = head;
while (current?.NextNode != null)
{
current = current.NextNode;
}
current.NextNode = newNode;
}
else // 리스트가 비어 있으면
{
head = newNode;
}
}
만약 위의 SinglyLinkedList Class에서 Head와 함께 Tail 필드를 추가하고 마지막 Node를 Tail에 저장한다면, Add 메서드에서 newNode 추가 시 Tail로 바로 마지막 Node를 찾을 수 있어 더욱 빠르고 쉽게 newNode를 추가할 수 있다.
📍 AddAfter(curNode, newNode) 메서드
newNode의 NextNode에 현재 Node의 NexNode를 먼저 할당하고, curNode의 NextNode에 newNode를 할당한다.
public void AddAfter(SinglyLinkedListNode<T> current, SinglyLinkedListNode<T> newNode)
{
if (head == null || current == null || newNode == null)
{
throw new InvalidOperationException();
}
newNode.NextNode = current.NextNode;
current.NextNode = newNode;
}
📍 GetNode(index) 메서드
Singly Linked List에서 특정 Index에 있는 Node를 반환한다.
만약 index가 Linked List의 범위를 범위나면 Null 반환.
배열은 index를 통해 즉시 그 인덱스에 해당하는 요소를 찾을 수 있지만(O(1)), Linked List는 해당 index 만큼 계속 이동해서 Node를 찾아야 하므로 O(n)의 시간 복잡도를 가진다.
public SinglyLinkedListNode<T> GetNode(int index)
{
var current = head;
if (current != null)
{
for (int i = 0; i < index; i++)
{
current = current.NextNode;
}
}
// 만약 index가 List Count보다 크면 null이 리턴 됨
return current;
}
🔔O(1)? O(n)? Big-O 시간 복잡도 점근 표기법을 알아 보러 가기
📍 Remove(removeNode) 메서드
삭제할 Node가 첫 Node일 경우, Head의 NextNode 즉 두번째 Node를 Head에 할당하고, 첫 Node가 아니면 해당 Node를 검색해서 삭제한다.
해당 Node를 검색할 때, Singly Linked List는 한방향이므로 List의 중간의 Node가 삭제되더라도 기존의 List의 요소들은 연결되어야 하기 때문에 먼저 삭제할 Node의 바로 이전 Node를 찾고 이전 Node의 NextNode에 삭제할 Node의 Next를 연결한 후에 삭제할 노드를 삭제해야한다.
public void Remove(SinglyLinkedListNode<T> removeNode)
{
if (head == null || removeNode == null)
return;
//삭제 할 노드가 첫 노드면
if (removeNode == head)
{
head = head.NextNode;
removeNode = null;
}
else // 첫 노드가 아니면 removeNode를 검색해서 삭제
{
var current = head;
// 한방향이므로 삭제할 노드의 바로 이전 노드를 검색
while (current?.NextNode != removeNode)
{
current = current.NextNode;
}
if (current != null)
{
// 이전 노드의 Next 노드에 삭제 노드의 Next 노드 할당
current.NextNode = removeNode.NextNode;
removeNode = null;
}
}
}
📍 (Option) RemoveAfter(previousNode) 메서드
이 메서드는 Remove(removeNode)의 변형 메서드다. 만약 작성한다면 삭제할 노드의 이전 Node를 검색 없이 이미 알고 있으므로, NextNode만 연결 해주면 된다.
public void RemoveAfter(SinglyLinkedListNode<T> preNode)
{
//삭제할 노드가 첫 노드일 경우에는 사용할 수 없음 - 애초에 preNode가 없으므로
if (head == null || preNode == null)
return;
var removeNode = preNode.NextNode;
if (removeNode != null)
{
preNode.NextNode = removeNode.NextNode;
removeNode = null;
}
}
하지만 삭제할 노드가 첫 노드일 경우 previousNode가 존재하지 않기 때문에 사용할 수 없다.
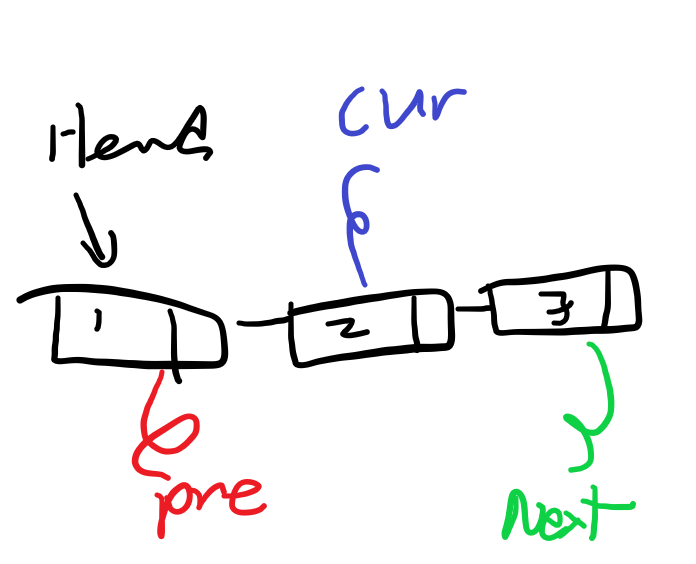
위의 이미지를 참고하자.
📍 Count() 메서드
Head부터 마지막 노트까지 이동하면서 Count를 증가시킨다.
public int Count()
{
int cnt = 0;
var current = head;
while (current != null)
{
cnt++;
current = current.NextNode;
}
return cnt;
}
📍 SinglyLinkedListApp - Singly Linked List 테스트 코드
public class SinglyLinkedListApp : MonoBehaviour
{
public int Length = 10;
public int SelectIndex = 0;
SinglyLinkedList<int> IntSinglyLinkedList = new();
void Start()
{
for (int i = 0; i < Length; i++)
{
var node = new SinglyLinkedListNode<int>(i);
IntSinglyLinkedList.Add(node);
}
}
[ContextMenu("단일 연결 리스트에서 입력한 인덱스의 노드 삭제 Remove")]
public void Remove()
{
var selectedNode = IntSinglyLinkedList.GetNode(SelectIndex);
if(selectedNode != null)
IntSinglyLinkedList.Remove(selectedNode);
}
[ContextMenu("단일 연결 리스트에서 입력한 인덱스의 노드 삭제 RemoveAfter")]
public void RemoveAfter()
{
var preNode = IntSinglyLinkedList.GetNode(SelectIndex - 1);
var removeNode = IntSinglyLinkedList.GetNode(SelectIndex);
if (preNode != removeNode)
IntSinglyLinkedList.RemoveAfter(preNode);
else
throw new ArgumentException();
}
[ContextMenu("현재 단일 연결 리스트의 요소 전부 출력")]
public void PrintAll()
{
for (int i = 0; i < IntSinglyLinkedList.Count(); i++)
{
var data = IntSinglyLinkedList.GetNode(i).Data;
Debug.Log($"SinglyLinkedListData :: {i} 번째 Data = {data}");
}
}
}
런타임에서 확인하기 쉽게 코드를 작성해봤다.
간단하게 설명하자면
public int Length = 10;
위의 Length 길이 만큼 연결리스트가 생성된다.
그리고 Start문에서 for 반복문을 돌며 노드를 생성하고, 연결 리스트에 추가한다.
public int SelectIndex = 0;
위의 변수는 삭제할 노드의 인덱스를 할당하는 변수다.
그 아래부터는 테스트 메서드인데 런타임에서 확인할 수 있도록 ContextMenu로 인스펙터 창에서 메서드를 호출할 수 있게 했다.
Remove() 메서드는 SinglyLinkedList Class의 Remove 메서드를 랩핑한 메서드이다.
RemoveAfter() 메서드는 SinglyLinkedList Class의 RemoveAfter 메서드를 호출하는 함수 인데, 인수로 PreNode를 넣기 때문에 사실상 첫번째 Node일 때는 사용할 수 없는 메서드다.
따라서 RemoveAfter() 메서드 본문에서 throw new ArgumentException();로 예외 처리를 했다.
PrintAll() 메서드는 현재 Singly Linked List 에 존재하는 모든 요소의 Data 필드를 출력하는 메서드다.
🔖 이중 연결 리스트 (Doubly Linked List)
이중 연결 리스트 (Doubly Linked List)는 List 안의 Node가 Prev Node와 Next Node를 가리키는 Pointer를 모두 가지고 있어 양방향으로 탐색이 가능한 자료 구조.
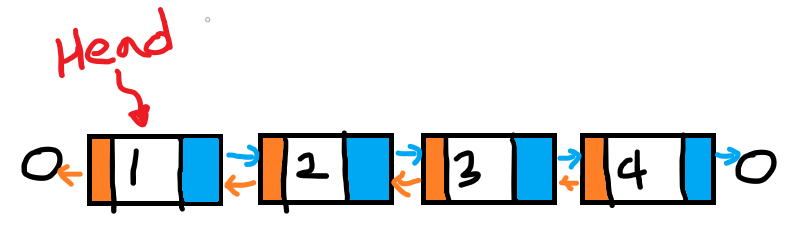
위의 이미지는 4개의 노드를 갖는 Doubly Linked List의 예시이다.
Doubly Linked List의 Node Class는 Node의 Data 필드와 Prev Node와 Next Node를 가리키는 2개의 Pointer를 가지고 있음.
📍 C# 으로 표현한 DoublyLinkedListNode Class
public class DoublyLinkedListNode<T>
{
public T Data { get; set; }
public DoublyLinkedListNode<T> PrevNode { get; set; }
public DoublyLinkedListNode<T> NextNode { get; set; }
public DoublyLinkedListNode(T data, DoublyLinkedListNode<T> prevNode = null, DoublyLinkedListNode<T> nextNode = null)
{
Data = data;
PrevNode = prevNode;
NextNode = nextNode;
}
}
Doubly Linked List 도 List의 처음을 가리키는 Head 필드가 필요하고, 경우에 따라 Tail 필드를 추가할 수도 있음.
Doubly Linked List의 기본적인 메서드는 Singly Linked List와 비슷하다.
1. Add(newNode) 메서드 - 새 Node를 추가.
2. AddAfter(curNode, newNode) 메서드 - 새 Node를 중간에 삽입.
3. GetNode(index) 메서드 - 지정한 위치에 있는 노드를 반환.
4. Remove(removeNode) 메서드 - 특정 노드를 지움.
5. 등등
📍 Add(newNode) 메서드
List가 비어 있을 경우 Head에 newNode를 할당한다.
null이 아니면 마지막 Node를 찾아 이동한 후 마지막 Node 다음에 newNode를 추가한다.
그리고 Singly Linked List와는 다르게 newNode의 prevNode에 현재 가리키고 있는 Node를 연결해주고, 양방향이기 때문에 newNode의 nextNode도 연결해줘야 하지만 nextNode가 존재하지 않기 때문에 Null을 할당한다.
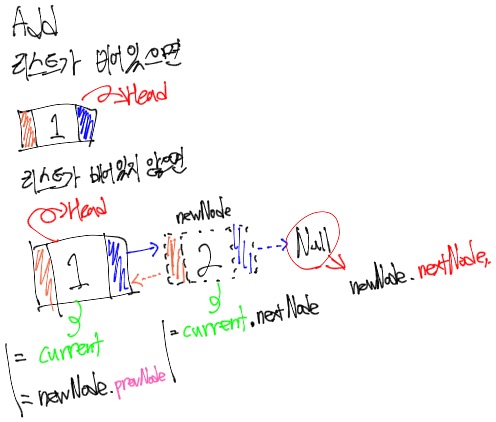
위의 이미지는 Head가 존재하는 상태에서 노드를 추가할 경우를 표현하고 있다.
이미지와 함께 코드를 보면 조금 더 이해가 쉬울 것이다.
public void Add(DoublyLinkedListNode<T> newNode)
{
if (head != null) // 리스트가 비어 있지 않으면
{
var current = head;
while (current?.NextNode != null)
{
current = current.NextNode;
}
// 추가할 때 Singly Linked List와는 달리 양방향 연결
current.NextNode = newNode;
newNode.PrevNode = current;
newNode.NextNode = null;
}
else // 리스트가 비어 있으면
{
head = newNode;
}
}
📍 AddAfter(curNode, newNode) 메서드
현재 노드(curNode)를 A, newNode를 B, curNode의 nextNode를 C라고 가정했을 때,
책에는 “A의 Next 레퍼런스를 B에 연결하고, C의 Prev 레퍼런스를 B에 연결하고, B의 Prev를 A에, B의 Next를 C에 연결한다.” 라고 적혀 있다.
뭐 의도한 건지는 모르겠으나, 한국어가 매우 불편하게 아주 어렵게 쓰여있다.
여기서 말하는 A의 Next 레퍼런스와, C의 Prev 레퍼런스는 무엇일까?
글로만 보면 이해가 안되니 이미지를 첨부하겠다.
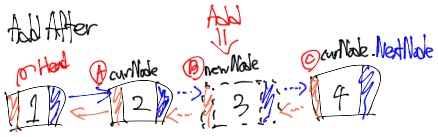
위의 이미지를 봤을 때, curNode 즉 A는 데이터 2를 담고 있는 2번째 노드다. newNode 즉 B는 Add하고 있는 3번째, 3을 담고 있는 3번째 노드다. curNode.NextNode 즉 C는 4번째, 4를 담고 있는 4번째 노드다.
여기서 A의 Next 레퍼런스를 찾아보자. A는 2를 담고 있는 2번째 노드고, 해당 노드의 Next 레퍼런스는 curNode.NextNode 즉 C가 된다.
그럼 C의 Prev 레퍼런스는? C는 4를 담고 있는 4번째 노드고, 해당 노드의 Prev 레퍼런스는 curNode.NextNode.PrevNode 즉 A가 된다.
그럼 다시 작성해보자
“curNode.NextNode를 B에 연결하고, curNode.NextNode.PrevNode를 B에 연결하고, B의 Prev를 curNode에, B의 Next를 curNode.NextNode에 연결한다.”
이걸 글을 보고 이해한대로 그대로 코드로 작성 하면 아래와 같다.
public void AddAfter(DoublyLinkedListNode<T> curNode, DoublyLinkedListNode<T> newNode)
{
if (head == null || curNode == null || newNode == null)
{
throw new InvalidOperationException();
}
newNode = curNode.NextNode;
newNode = curNode.NextNode.PrevNode;
curNode = newNode.PrevNode;
curNode.NextNode = newNode.NextNode;
}
위와 같이 작성하면 아주 우스꽝스러운 일이 벌어질 것이다. 그리고 당연히 틀렸다.
난 이 책을 비난하고자가 아닌 개인적으로 구매한 책을 보고 느낀대로 적는 것이다. 누구에게는 별로 중요한 일이 아닐 수도 있지만, 나는 이 글을 보고 정말로 저렇게 이해했다.
“호스를 수도꼭지에 연결하다.”
무엇이 주체일까? 수도꼭지에 호스를 연결하는 것이다.
“curNode.NextNode를 B에 연결하다.”
무엇이 주체일까? B에 curNode.NextNode를 연결하는 것이다.
따라서 위와 같이 이해했다.
그런데 우리는 B에 curNode.NextNode를 연결하는게 아닌 curNode.NextNode 에 B를 연결해야 한다.
왜냐하면 B가 curNode 다음에 새로 들어오는 녀석이니까 당연히 curNode.NextNode 는 B가 될 것이고, 그말은 curNode.NextNode에 B를 연결해야 하는게 아닌가? 갑자기 화가 나네?
무튼 마무리를 짓자면,
curNode.NextNode에 B를 연결하고, curNode.NextNode.PrevNode에 B를 연결하고, B의 Prev에 curNode를, B의 Next에 curNode.NextNode를 연결한다.
근데 또 심지어 이것도 이상하다.
그대로 코드를 작성해 보겠다.
public void AddAfter(DoublyLinkedListNode<T> curNode, DoublyLinkedListNode<T> newNode)
{
if (head == null || curNode == null || newNode == null)
{
throw new InvalidOperationException();
}
curNode.NextNode = newNode;
curNode.NextNode.PrevNode = newNode;
newNode.PrevNode = curNode;
newNode.NextNode = curNode.NextNode;
}

응 뭔가 이상해, 이거 아니야
첫번째 curNode.NextNode = newNode 를 해줬는데 4번째 에서 newNode.NextNode = curNode.NextNode 를 할당하면 newNode.NextNode = newNode 랑 똑같은 얘기인데??
newNode 다음 노드가 newNode인데 말이 되나? 심지어 거꾸로 할당한다고 해도 말이 안되네?
예시) newNode = curNode.NextNode
그냥 애초에 말이 안되는 걸, 더 어려운 한국말로 쓰여있어서 이해하는데 매우 어려웠다.
아래의 이미지를 참고하면서 이해를 해보자. (하도 짜증나서 그림으로 그림)
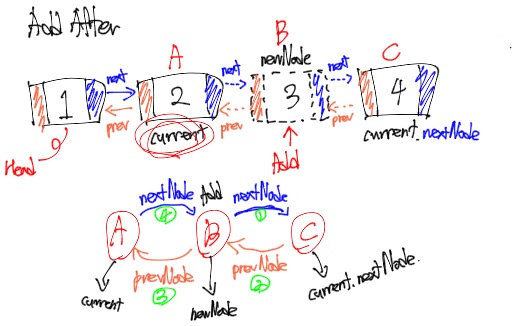
아래에 친절하게 순서까지 적어줬다.
그러니까 뭐라고?
B의 Next(newNode.NextNode)에 C(curNode.NextNode)를 연결하고, C의 Prev(curNode.NextNode.PrevNode)에 B(newNode)를 연결한다.
그리고 B의 Prev(newNode.PrevNode)에 A(curNode)를 연결하고, A의 Next(curNode.NextNode)에 B(newNode)를 연결한다.
public void AddAfter(DoublyLinkedListNode<T> curNode, DoublyLinkedListNode<T> newNode)
{
if (head == null || curNode == null || newNode == null)
{
throw new InvalidOperationException();
}
newNode.NextNode = curNode.NextNode;
curNode.NextNode.PrevNode = newNode;
newNode.PrevNode = curNode;
curNode.NextNode = newNode;
}
이걸 왜 레퍼런스니 뭐니 하면서 개념을 이중으로 나눠서 설명하고, 심지어 문장자체가 잘못되서 이렇게 이해하기 어렵게 만들었을까?
제발 의도적으로 그런거라 믿고 싶다.
어쨌든 해당 작업은 각 Node의 prevNode와 nextNode만 수정해주기 때문에, O(1)의 시간 복잡도를 가진다.
O(1) 상수 시간은 뭐다? 최고의 효율을 가진 알고리즘이라는 증표
📍 Remove(removeNode) 메서드
단일 연결 리스트와는 달리, 삭제시 이전 노드 검색할 필요가 없어서 즉시 연결가능.
public void Remove(DoublyLinkedListNode<T> removeNode)
{
if (head == null || removeNode == null)
return;
//삭제 할 노드가 첫 노드면
if (removeNode == head)
{
head = head.NextNode;
if (head != null)
{
head.PrevNode = null;
}
}
else // 첫 노드가 아니면, prevNode와 nextNode를 연결
{
removeNode.PrevNode.NextNode = removeNode.NextNode;
if (removeNode.NextNode != null)
{
removeNode.NextNode.PrevNode = removeNode.PrevNode;
}
}
removeNode = null;
}
마찬가지로 시간복잡도는 O(1) 상수 시간이다.
📍 GetNode(index) 메서드
해당 메서드는 인덱스만큼 계속 이동하면서 노드를 찾으므로 O(n)의 시간복잡도를 가진다.
public DoublyLinkedListNode<T> GetNode(int index)
{
var current = head;
if (current == null)
return current;
for (var i = 0; i < index; i++)
{
current = current.NextNode;
}
// 만약 index가 List Count보다 크면 null이 리턴 됨
return current;
}
📍 Count() 메서드
이것도 노드 마지막까지 이동하면서 Counting 하는 것이므로 0(n)의 시간복잡도를 가짐.
public int Count()
{
int cnt = 0;
var current = head;
while (current != null)
{
cnt++;
current = current.NextNode;
}
return cnt;
}
📍 DoublyLinkedListApp - Doubly Linked List 테스트 코드
public class DoublyLinkedListApp : MonoBehaviour
{
public int Length = 4;
public int SelectIndex = 0;
DoublyLinkedList<int> IntDoublyLinkedList = new();
void Start()
{
for (int i = 0; i < Length; i++)
{
var node = new DoublyLinkedListNode<int>(i);
IntDoublyLinkedList.Add(node);
}
}
[ContextMenu("이중 연결 리스트에서 입력한 인덱스 뒤에 int 값 100을 가지고 있는 Node 추가 AddAfter")]
public void AddAfter()
{
var selectedNode = IntDoublyLinkedList.GetNode(SelectIndex);
var node = new DoublyLinkedListNode<int>(100);
IntDoublyLinkedList.AddAfter(selectedNode, node);
}
[ContextMenu("이중 연결 리스트에서 입력한 인덱스의 노드 삭제 Remove")]
public void Remove()
{
var selectedNode = IntDoublyLinkedList.GetNode(SelectIndex);
if(selectedNode != null)
IntDoublyLinkedList.Remove(selectedNode);
}
[ContextMenu("이중 연결 리스트에서 입력한 인덱스의 노드 삭제 RemoveAfter")]
public void RemoveAfter()
{
var preNode = IntDoublyLinkedList.GetNode(SelectIndex - 1);
var removeNode = IntDoublyLinkedList.GetNode(SelectIndex);
if (preNode != removeNode)
IntDoublyLinkedList.RemoveAfter(preNode);
else
throw new ArgumentException();
}
[ContextMenu("이중 연결 리스트의 요소 전부 출력")]
public void PrintAll()
{
for (int i = 0; i < IntDoublyLinkedList.Count(); i++)
{
var data = IntDoublyLinkedList.GetNode(i).Data;
Debug.Log($"DoublyLinkedListData :: {i} 번째 Data = {data}");
}
}
}
테스트 코드는 위의 단일 연결 리스트와 비슷하다.
다른 점은 AddAfter 메서드가 추가되었다.
해당 메서드를 실행하면 SelectIndex 변수에 받은 int 정수형 값을 인덱스를 기준으로 IntDoublyLinkedList에서 해당하는 노드를 찾아 바로 다음에 100의 데이터를 가진 노드를 추가해주는 메서드다.
본의 아니게 너무 길어져서 2개로 나눠 포스팅해야겠다.
📢 오늘의 한마디
⚡한글은 너무 어려워 차라리 영어가 더 쉬울 때도 있다.
이 게시물에는 지극히 주관적인 생각이 포함되어 있습니다.
오류나 틀린 부분, 또는 수정해야 할 부분이 있다면 언제든지 댓글 혹은 메일로 지적 부탁드립니다.
Comment